在安装anaconda后,python版本为3.7,由于很多包不支持或者支持效果不好(例如TensorFlow等),所以要降到3.6版本由于使用shell命令使用anaconda创建的环境可能出现问题,所以要在base环境下安装python3.6,可以使用以下命令:
1 | conda install python=3.6 |
安装完成后,使用python(或者python3)命令打开python3.6.8,使用pip(不是pip3)可以直接进行包管理。
在安装anaconda后,python版本为3.7,由于很多包不支持或者支持效果不好(例如TensorFlow等),所以要降到3.6版本由于使用shell命令使用anaconda创建的环境可能出现问题,所以要在base环境下安装python3.6,可以使用以下命令:
1 | conda install python=3.6 |
安装完成后,使用python(或者python3)命令打开python3.6.8,使用pip(不是pip3)可以直接进行包管理。
输出环境变量1
2snjl@VM-0-2-ubuntu:~$ echo $PATH
/home/snjl/bin:/home/snjl/.local/bin:home/snjl/anaconda3/bin:/home/snjl/anaconda3/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
使用whereis查看目录:1
2
3
4
5
6
snjl@VM-0-2-ubuntu:~$ whereis python2
python2: /usr/bin/python2.7 /usr/bin/python2 /usr/lib/python2.7 /etc/python2.7 /usr/local/lib/python2.7 /usr/share/man/man1/python2.1.gz
snjl@VM-0-2-ubuntu:~$ whereis python3
python3: /usr/bin/python3.5 /usr/bin/python3 /usr/bin/python3.5m /usr/lib/python3.5 /usr/lib/python3 /etc/python3.5 /etc/python3 /usr/local/lib/python3.5 /usr/share/python3 /home/snjl/anaconda3/bin/python3.7-config /home/snjl/anaconda3/bin/python3 /home/snjl/anaconda3/bin/python3.7m-config /home/snjl/anaconda3/bin/python3.7 /home/snjl/anaconda3/bin/python3.7m /usr/share/man/man1/python3.1.gz
snjl@VM-0-2-ubuntu:~$
创建软链接:1
ls -s /usr/bin/python3.5 /user/bin/python3
这样可以直接调用python3,不用调用python3.5。
官网下载。
下载安装mongo后,在server的版本路径地址下添加文件夹data,data内建立文件夹db,用来存储mongo的配置文件和数据库:
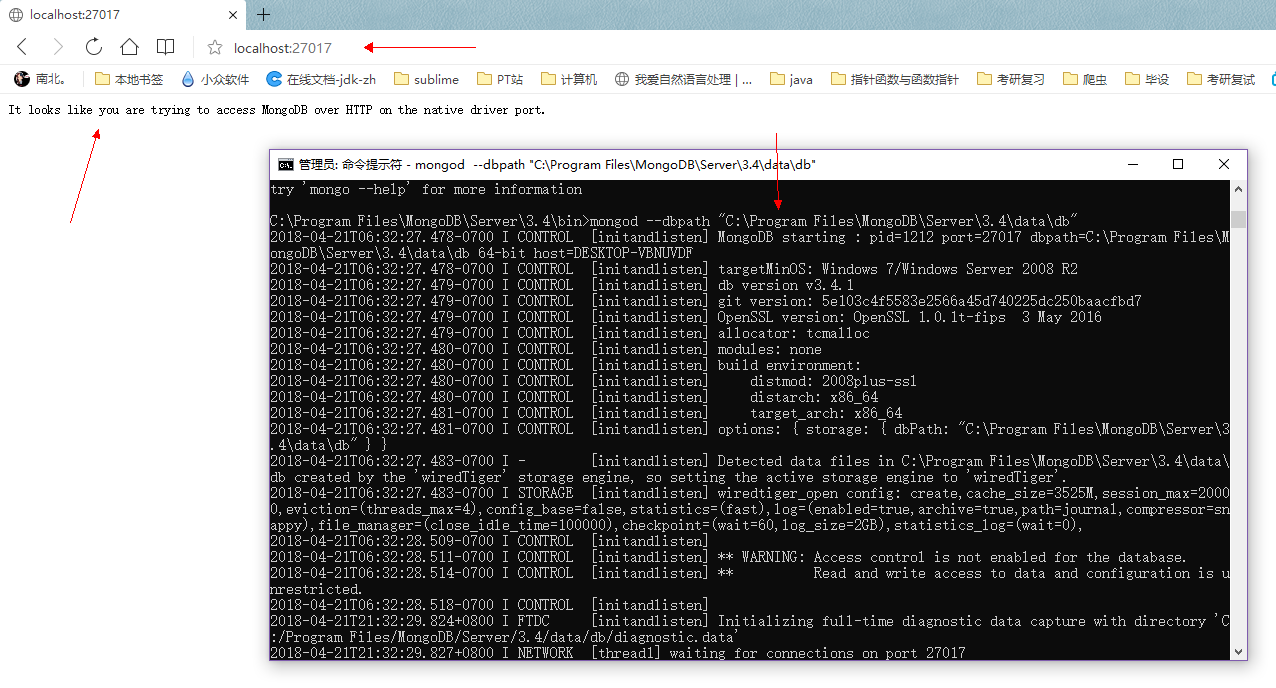
之后在bin路径下打开cmd或cmder(管理员权限),输入1
mongod --dbpath "C:\Program Files\MongoDB\Server\3.4\data\db"
即使用mongod命令指定db的路径,如下所示,在浏览器中输入localhost:27017(mongo默认端口)看到显示就是配置正确:
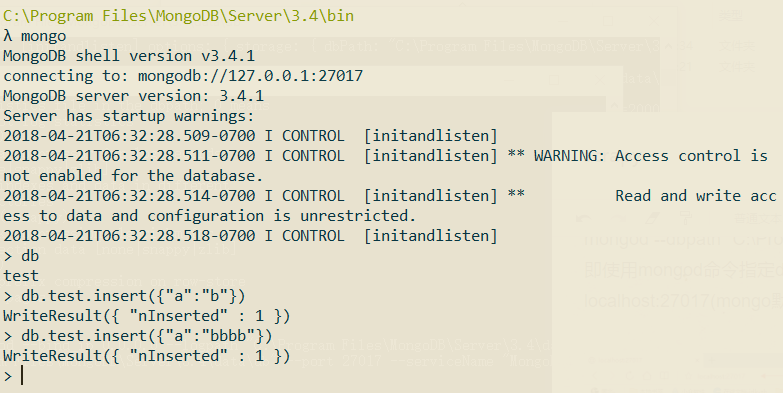
开启另一个命令行,在bin路径下输入mongo即可进入数据库:
进入server文件夹-3.4-data,创建logs文件夹,里面创建mongo.log日志文件,然后在bin文件夹中,使用管理员的cmd中输入:1
mongod --bind_ip 0.0.0.0 --logpath "C:\Program Files\MongoDB\Server\3.4\data\logs\mongo.log" --logappend --dbpath "C:\Program Files\MongoDB\Server\3.4\data\db" --port 27017 --serviceName "MongoDB" --serviceDisplayName "MongoDB" --install
如果mongo的路径中含有空格,一定要加双引号,这里选定了log的路径,且指定为append方式添加日志,指定端口27017,指定服务名称MongoDB,显示名称也是MongoDB。


未显示报错即成功。
打开计算机的服务,查找Mongo:
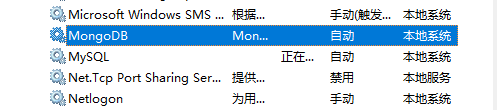
右键启动后,在浏览器输入localhost:27017即可访问,在日志文件也能看到访问信息:

安装robo 3T,连接localhost的27017端口,如下显示就是连接正确:
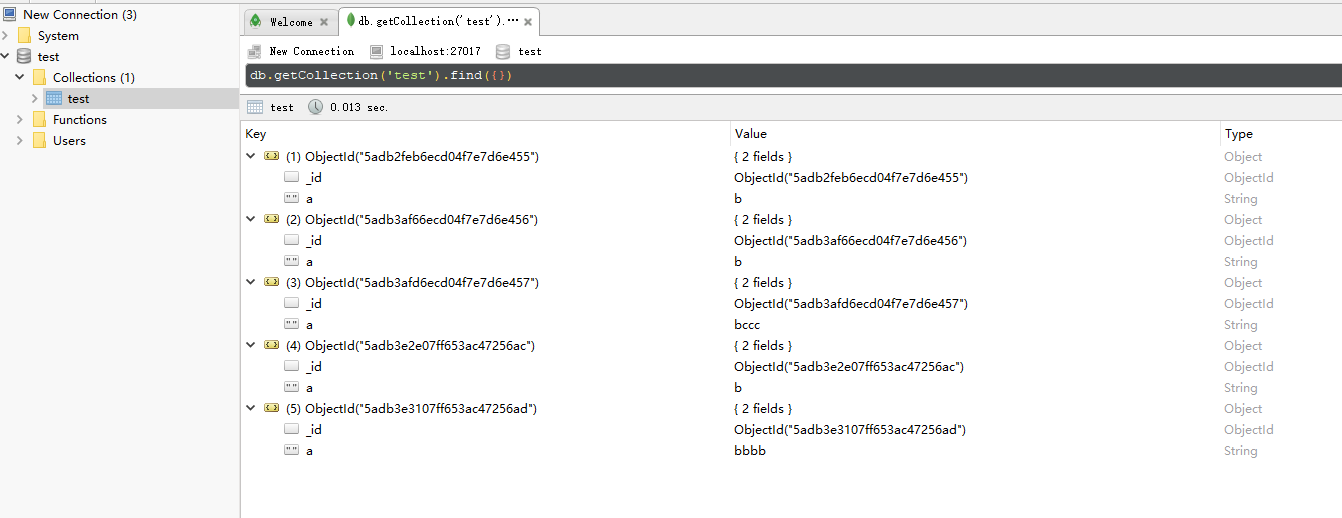
1 | sudo apt install mongodb-server |
1 | snjl@VM-0-2-ubuntu:~$ mongo |
1 | > use local |
mongodb远程连接配置如下:
命令1
vim /etc/mongodb.conf
把 bind_ip=127.0.0.1 这一行注释掉或者是修改成 bind_ip=0.0.0.0
命令:1
/etc/init.d/mongodb restart
或者1
service mongodb restart
命令:1
iptables -A INPUT -p tcp -m state --state NEW -m tcp --dport 27017 -j ACCEPT
要连接的IP:134.567.345.23
命令:1
mongo 134.567.345.23:27017
这样就可以连接到134.567.345.23的mongodb/test的数据库
1 | > use admin |
命令:1
mongo 134.567.345.23:27017/admin -uusername -p
输入password即可
官方文档中,新版本的 Flask(>=0.11) 运行方式和以前有所不同,但是按照官方文档,可能会碰到坑的地方:1
Error: Could not locate Flask application. You did not provide the FLASK_APP environment variable.
问题出在终端上面:1
2
3
4
5
6
7
8
9
10# run.py
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello World!"
if __name__ == "__main__":
app.run(debug=True)
运行:1
2
3$ export FLASK_APP=run.py
$ flask run
* Running on http://127.0.0.1:5000/
如果你的 Terminal 用的是 cmd,那么运行:1
2
3> set FLASK_APP=run.py
> flask run
* Running on http://127.0.0.1:5000/
如果你的 Terminal 用的是 powershell,那么运行:1
2 > $env:FLASK_APP=".\run.py" | flask run
* Running on http://127.0.0.1:5000/
项目地址:https://github.com/snjl/python.flask.templates.git
我想要我的首页头部有一个欢迎用户的显示。当然现在应用中还没有用户的概念,在后面会加上。取而代之的是,我将会使用一个 mock 用户(模拟用户),我用一个 Python 字典来实现:1
user = {'username': 'snjl'}
创建一些模拟对象是一项比较有用的技术,这样使得你能专心于应用的一部分,而不用担心系统的其他部分还不存在。我想为我的应用设计一个首页,但是我不想被系统目前没有用户系统而烦恼,因此我模拟了一个用户对象,这样我就可以继续我的工作了。
视图函数返回了一个简单的字符串。我要做的就是将这个返回的字符串展开成一个完整的 HTML 页面。比如这样:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21from flask import Flask
app = Flask(__name__)
@app.route('/')
@app.route('/index')
def index():
user = {'username': 'snjl'}
return '''
<html>
<head>
<title>Home Page - Home</title>
</head>
<body>
<h1>Hello, ''' + user['username'] + '''!</h1>
</body>
</html>'''
if __name__ == '__main__':
app.run(debug=True)
上述将 HTML 传递到浏览器的方式不是很好。当我想将用户的文章返回的时候,视图函数将会变得复杂,而且文章还会经常改变。而且应用还会有与其他 URL 绑定的视图函数,那么想象以下将来有一天我要改变应用的布局,那么我就得在每个视图函数中更新 HTML。所以这绝不是一个应对应用规模不断增长的方案。
如果能将应用的逻辑和 web 页面的展示和布局分开的话,所有的东西都变得易于组织,甚至可以雇佣一个 web 页面设计者来创造非常牛逼的页面,而你只需要使用 Python 完成应用的逻辑代码。
模板帮助实现了表示层和业务逻辑的分离。在 Flask 中,模板被写在单独的文件中,存储在应用的包的 templates 文件夹中。因此确保你在项目文件夹下,创建 templates 文件夹。
下面你可以看到你的第一个模板,和上面 index() 视图函数返回的 HTML 页面很相似,将这个文件保存在 app/templates/index.html1
2
3
4
5
6
7
8<html>
<head>
<title>{{ title }} - Home</title>
</head>
<body>
<h1>Hello, {{ user.username }}!</h1>
</body>
</html>
这一个标准的,非常简单的 HTML 页面。里面值得注意的是,两个花括号括起来的用于动态内容的部分。这表示里面的内容是变量,而且之后再运行的时候才能生成。
现在页面的展示已经放到了 HTML 模板中,视图函数就被简化了:
1 | from flask import render_template |
是不是看起来更好了。在应用中试试看看模板是怎么工作的。一旦你在浏览器中载入了这个页面,你可能想看看 HTML 源代码和以前有什么不一样。
将模板转换成完整的 HTML 页面的过程叫做渲染(rendering)。为了渲染模板,我必须从 Flask 中导入一个函数叫做 render_template,这个函数将模板名字和一个模板参数的变量列表作为参数,然后返回同样的模板,但是已经用变量将模板中的占位符给替换了。
render_template() 函数调用了 Jinja2 模板引擎,该引擎是和 Flask 绑定在一起的。Jinja2 将会使用通过 render_template 函数传递进来的参数来替代对应的块。
你已经看到了 Jinja2 在渲染的时候是如何将真实的值替换占位符的,但是这只是 Jinja2 众多强大功能之一。比如,模板同样支持控制语句。index.html 的下一个版本就是增加一个条件语句。
1 | <html> |
现在模板变得更智能了。如果视图函数忘记传递 title 参数,模板会使用默认值来渲染而不是一个空的 title。你可以通过移除 title 参数来查看条件语句是如何工作的。
登录的用户可能想看在首页的所有用户最近的文章列表。那么应该如何扩展应用来支持这个功能呢。
同样,我会创建一些模拟的用户对象和一些文章对象来展示。
1 | from flask import render_template |
使用了个列表,里面每个元素都是一个字典,并且都包含 author 和 body 字段。当我要实现用户和文章的时候我也会尽量保留现在的字段名字,所以在之后我在设计和测试之中使用的这些对象依然有效。
在模板方面我必须得解决一个新的问题。posts 列表可能有任意多个元素,它取决于视图函数决定多少个 posts 将会在页面展示。模板不能对有多少 posts 做任何假定,因此它必须以通用的方式来渲染任意视图函数传递给它的 posts。
对于这个问题,Jinja2 提供了 for 控制结构:
1 | <html> |
大多数 web 应用在页面顶部都会有一个导航栏,上面放置一些比较常用的链接,比如编辑个人资料,登录登出等。我可以很容易的给 index.html 模板来添加一个导航栏,但是随着应用的规模增长我需要将同样的导航栏放到其他页面上。但是我不想在多个 HTML 模板中维护数个一样的导航栏。not repeat yourself 不要重复你自己!
Jinja2 拥有模板继承特性就是来解决这个问题的。在本质上,你要做的就是将所有模板共同的东西拿到一个基础模板中,然后其他模板从这个基础模板派生。
所以我要做的就是定义一个叫 base.html 的基础模板,其包含了一个简单的导航栏以及之前实现的简单逻辑。你需要将下面的代码保存到app/template/base.html 模板中1
2
3
4
5
6
7
8
9
10
11
12
13
14<html>
<head>
{% if title %}
<title>{{ title }} - Microblog</title>
{% else %}
<title>Welcome to Microblog</title>
{% endif %}
</head>
<body>
<div>Microblog: <a href="/index">Home</a></div>
<hr>
{% block content %}{% endblock %}
</body>
</html>
在这个模板中我使用了 block 控制语句来定义派生模板可以插入的位置。block 的名字是唯一的,这样派生模板就可以在提供他们的内容时候引用。
在有了基础模板,我现在可以让 index.html 来继承 base.html1
2
3
4
5
6
7
8{% extends "base.html" %}
{% block content %}
<h1>Hi, {{ user.username }}!</h1>
{% for post in posts %}
<div><p>{{ post.author.username }} says: <b>{{ post.body }}</b></p></div>
{% endfor %}
{% endblock %}
既然 base.html 现在可以承担通用的页面结构,我将这些元素从 index.html 中移除了,只留下了内容部分。extends 语句在两个模板间建立了继承关系,因此 Jinja2 知道当要渲染 index.html 的时候,需要将其嵌入到 base.html。两个模板会来用名字 content 来匹配 block 语句,这也是 Jinja2 为什么知道如何将两个模板合并成一个。现在如果我需要为应用创建其他页面的话,我可以从同样的 base.html 来派生模板,这也是我可以使得应用的所有页面都看起来相似但是又不会感觉到重复。
项目地址:https://github.com/snjl/python.spider.jiepai.git
https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D
访问网址后,会发现列表页有多种形式,第一种是视频,第二种是广告,第三种是所有图片在一个网页里面,第四种是图片需要跳转,我们做的是第四种。
通过f12开发者工具可以看到比较详细的信息。
点preserve log,可以刷新时保留记录,点XHR,可以看到传输过来的ajax数据。
列表是通过ajax传输过来的,参数有多个,在python爬取的时候需要传输:1
2
3
4
5
6
7
8
9
10
11data = {
'aid': 24,
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'cur_tab': 3,
'from': 'gallery',
'pd': 'synthesis',
}
其中keyword是可以改变的,offset是偏移值,一般是为20的倍数,因为每次json传输20个数据。
列表页需要获取的是每个详情页的title和url。
分析详情页,可以发现每次跳转网页实际上不是ajax交互,而是在初始的网页中有数据,如下所示:1
2
3 gallery: JSON.parse("{\"count\":9,\"sub_images\":[{\"url\":\"http:\\/\\/p1.pstatp.com\\/origin\\/pgc-image\\/e4de890cc2084bc5b3557ee5b6ea0ed9\",\"width\":800,\"url_list\":[{\"url\":\"http:\\/\\/p1.pstatp.com\\/origin\\/pgc-image\\/e4de890cc2084bc5b3557ee5b6ea0ed9\"},
···
所以实际上已经把图的地址写在doc里,拿到网页的url,然后通过正则获取就可以得到地址。
列表页需要两个函数,第一个是获取列表页的的response.text(需要进行错误处理),第二个是对列表页进行解析,获取到需要抓取的详情页的一些信息。
详情页里,需要通过正则获取到所有需要下载的链接,所以也是两个函数,一个获取详情页的response.text,一个获取详情页中的下载信息。
数据库使用mongodb,这里的代码可以插入在详情页的下载信息或者main函数中每次处理完一个详情页信息后进行存储;
图片下载同样处理,也可以放在获取到详情页的下载链接后的for循环遍历。
获取列表页response.text1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24def get_page_index(offset, keyword):
data = {
'aid': 24,
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'cur_tab': 3,
'from': 'gallery',
'pd': 'synthesis',
}
url = 'https://www.toutiao.com/api/search/content/?' + urlencode(data)
print(url)
try:
response = requests.get(url=url, headers=headers)
if response.status_code == 200:
response.encoding = 'utf8' # 原编码不是utf8,会有一定乱码
return response.text
return None
except RequestException as e:
print(e)
print("请求json出错")
return None
传入keyword,offset获取列表页text。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17def parse_page_index(html):
try:
data = json.loads(html)
# 判断data不为空,且'data'在keys中,并且data['data']不为空
if data and 'data' in data.keys() and data['data']:
items = data['data']
for item in items:
# 判断abstract为空,且app_info存在,且item['app_info']['db_name']为SITE
if item and 'abstract' in item.keys() and \
item['abstract'] == '' and 'app_info' in item.keys() \
and item['app_info']['db_name'] == 'SITE':
yield {
'title': item['title'],
'url': item['article_url']
}
except JSONDecodeError as e:
print(e)
由于拿到的是ajjax的json数据,所以可以通过json.loads()方法解析到数据,然后判断data是否为空,data里面是否有‘data’字段,如果有的话判断里面的每一个item是否有’abstract’字段和’app_info’字段,如果有,里面字段’db_name’的值为SITE(其实还是有误差)的才是第四类,通过这种方式获取的列表页信息才是比较干净的数据。最后返回title和url数据。
1 | def get_page_detail(url): |
获取详情页response.text代码。1
2
3
4
5
6
7
8
9
10def parse_page_detail(html):
images_pattern = re.compile('gallery: JSON.parse\("(.*?)"\)')
result = re.search(images_pattern, html)
if result:
result_data = re.sub(r'\\', '', result.group(1))
data = json.loads(result_data)
images = [sub_image['url'] for sub_image in data['sub_images']]
for image in images:
download_image(image)
return images
通过正则,获取内容后,由于反斜杠‘\’的存在影响了我们的进一步操作,因此,有必要把反斜杠去掉,需要注意的是,这里显示的每一个反斜杠,实际上源字符串中都有两个反斜杠,还有一个反斜杠是用来转义的,故print是并不显示。
因此,我们要实际上要去掉的是两个连续的反斜杠,使用re.sbu(r’\’,’’,results)进行替换
处理后,获得的就是一个images的url的list列表(此处还调用了一个下载图片的函数,后续会介绍),然后返回。
数据库可以使用配置类,所以另建一个配置文件config.py1
2
3
4
5
6
7
8MONGO_URL = 'localhost'
MONGO_DB = 'toutiao'
MONGO_TABLE = 'toutiao'
GROUT_START = 1
GROUP_END = 40
KEYWORD = '街拍'
然后在使用mongo的时候调用1
2
3
4
5
6
7
8
9
10# 生成mongodb数据库对象
client = pymongo.MongoClient(MONGO_URL,connect=False)
db = client[MONGO_DB]
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print("存储到mongodb成功", result)
return True
return False
图片下载1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def download_image(url):
print("正在下载", url)
try:
response = requests.get(url=url, headers=headers)
if response.status_code == 200:
save_image(response.content)
return None
except RequestException as e:
print(e)
print("请求图片出错", url)
return None
def save_image(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
下载图片使用md5计算名称,存到当前路径。
1 | def main(offset): |
main函数参数为offset,keyword由配置文件传入。
main函数逻辑是,获取offset(偏移)后,获取这个json的数据并且解析出每一个item(dict类型,含有url和title),通过get_page_detail解析出每个网页的html,通过parse_page_detail解析出images,并且通过save_to_mongo存储到mongodb。
在调用parse_page_detail的时候就已经下载了图片。
1 | if __name__ == '__main__': |
如果要多进程,使用:1
2
3
4if __name__ == '__main__':
groups = [x * 20 for x in range(GROUT_START, GROUP_END + 1)]
pool = Pool()
pool.map(main, groups)
groups为config.py中设置的1-40,groups实际上值为[20,40,60,…,400]。
Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
去菜鸟教程找redis的下载地址(https://github.com/MSOpenTech/redis/releases),下载msi。之后找redis desktop manager下载安装。
在github上搜redis desktop,安装一个可视化界面:
https://github.com/uglide/RedisDesktopManager
默认端口为6379。
1 | sudo apt install redis-server |
使用1
2
3
4
5snjl@VM-0-2-ubuntu:~$ redis-cli
127.0.0.1:6379> set 'a' 'b'
OK
127.0.0.1:6379> get 'a'
"b"
设置远程连接和密码1
sudo vim /etc/redis/redis.conf
找到里面的bind 127.0.0.1,改为0.0.0.0,找到requirepass,取消注释后把后面的内容修改为密码。
重启服务1
sudo service redis restart
这时候登录需要加入密码:1
redis-cli -a PASSWORD
此时才可以用get ‘a’获取值。
https://github.com/snjl/python.flask.helloworld.git
使用pycharm生成一个flask项目,项目结构如下:1
2
3
4helloworld
static
templates
helloworld.py
其中helloworld.py代码:1
2
3
4
5
6
7
8
9from app import app
@app.route('/')
@app.route('/index')
def index():
return "Hello, World!"
if __name__ == '__main__':
app.run(debug=True)
使用app.run(debug=True),可以直接在pycharm中跑,而且这样在修改网页模版的时候,刷新网页内容会直接更新。
这个视图函数其实很简单,这是返回了这个 Hello, World! 字符串。在函数定义上面的是两个装饰器,Python 中特别的语法糖。装饰器改变或者增加了被装饰函数的功能。一个装饰器经常会用到的地方是将函数注册为某些事件的回调函数。在这里,@app.route 装饰器创建了以参数给定的 URL 和视图函数的联系。这里有两个装饰器,将 / 和 /index 和 index 函数关联起来了。这意味着,不论 web 浏览器向哪个 URL 发送请求,Flask 将会调用这个函数,然后将返回值作为对浏览器的响应。
1 | > set FLASK_APP=run.py |
函数写成:1
2
3
4
5
6from app import app
@app.route('/')
@app.route('/index')
def index():
return "Hello, World!"
在服务器初始化完成之后,它就在等待来自客户端的链接了。flask run 的输出表示服务器正在运行在 127.0.0.1 这个 IP 地址上,这个总是你本机的地址。这个地址很常用,因此有一个更简单的别名: localhost。服务器会监听特定的端口,在生产环境上的服务器一般会监听 443 端口,或者在不需要加密的时候使用 80 端口,但是这些都需要管理员权限。因为应用在开发环境上运行,Flask 使用了可用的 5000 端口。下面在浏览器中输入下面的 URL:http://localhost:5000/,当然你也可以输入下面这个: http://localhost:5000/index
两个不同的 URL 会返回同样的东西。但是你输入其他 URL 将会发生一个 404 错误,因为只有上面两个 URL 可以被应用识别。
提取的站点URL为http://maoyan.com/board/4,提取的结果会以文件形式保存下来。
分为几个部分,分别是:
1 | def get_one_page(url, headers): |
传入url和headers,使用异常类进行捕获。
1 | def parse_one_page(html): |
分析网页可以知道dd标签分割每个项目,将单个项目拿出来,使用BeautifulSoup进行解析,使用yield返回数据。
1 | def write_to_file(content): |
使用with,可以保证异常关闭;使用a,可以保证写入不清空;使用utf8和json存储时的ensure_ascii=False,可以使写入数据为utf8编码。
1 | def main(offset): |
跳转页面,可以发现网址从http://maoyan.com/board/4变为了http://maoyan.com/board/4?offset=10。
比之前的URL多了一个参数,那就是offset=10,而目前显示的结果是排行11~20名的电影,初步推断这是一个偏移量的参数。再点击下一页,发现页面的URL变成了http://maoyan.com/board/4?offset=20,参数offset变成了20,而显示的结果是排行21~30的电影。
由此可以总结出规律,offset代表偏移量值,如果偏移量为n,则显示的电影序号就是n+1到n+10,每页显示10个。所以,如果想获取TOP100电影,只需要分开请求10次,而10次的offset参数分别设置为0、10、20、…90即可,这样获取不同的页面之后,再用正则表达式提取出相关信息,就可以得到TOP100的所有电影信息了。
最后,实现main()方法来调用前面实现的方法,将单页的电影结果写入到文件。相关代码如下:1
2
3if __name__ == '__main__':
for i in range(10):
main(i*10)
如果需要考虑爬虫过快,可以在后面加一个sleep:1
2
3
4if __name__ == '__main__':
for i in range(10):
main(i*10)
time.sleep(1)
将main的代码改成:1
2
3
4
5if __name__ == '__main__':
# 使用多进程
pool = Pool()
pool.map(main, [i * 10 for i in range(10)])
引入1
from multiprocessing import Pool
如果使用多进程,想要防止爬虫过快,可以在main函数里加一个sleep1
2
3
4
5
6
7
8
9
10
11
12def main(offset):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/71.0.3578.98 Safari/537.36'
}
url = 'https://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url, headers)
for item in parse_one_page(html):
print(item)
write_to_file(item)
time.sleep(1)
项目地址:https://github.com/snjl/python.scrapy.middlewarestest.git
下载器中间件是介于Scrapy的request/response处理的钩子框架。 是用于全局修改Scrapy request和response的一个轻量、底层的系统。
修改request、response,相当于request和response加了一层处理后再给Spiders,例如request发送时使用cookie、代理等,response返回时增加状态码等,还有异常处理,例如无法正常访问时加一个异常处理,增加一个代理后再次请求request,使用代理后就正常访问了。
编写下载器中间件十分简单。每个中间件组件是一个定义了以下一个或多个方法的Python类:1
class scrapy.downloadermiddlewares.DownloaderMiddleware
当每个request通过下载中间件时,该方法被调用。
process_request() 必须返回其中之一: 返回 None 、返回一个 Response 对象、返回一个 Request 对象或raise IgnoreRequest 。
如果其返回 None ,Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用, 该request被执行(其response被下载)。(一般返回None,就是已经在request里加了东西,希望它继续处理,继续调用其他中间件的process_request())
如果其返回 Response 对象,Scrapy将不会调用 任何 其他的 process_request() 或 process_exception() 方法,或相应地下载函数; 其将返回该response。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。
如果其返回 Request 对象,Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用。
如果其raise一个 IgnoreRequest 异常,则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录(不同于其他异常那样)。
参数: